Mục lục bài viết
- Tổng Quan về Llama 3.3 70B
- Các Tính Năng Chính
- Hướng Dẫn Tích Hợp
- Khả Năng Triển Khai
- Lưu Ý Quan Trọng
- Kết Luận
Meta đã chính thức ra mắt mô hình Llama 3.3 70B trên nền tảng Amazon Bedrock.
Tôi chia sẻ chi tiết về mô hình này với tham khảo từ trang bên dưới
https://aws.amazon.com/about-aws/whats-new/2024/12/metas-llama-3-3-70b-model-amazon-bedrock
Tổng Quan về Llama 3.3 70B
Llama 3.3 70B là phiên bản mới nhất trong dòng sản phẩm Llama của Meta, được tối ưu hóa đặc biệt cho hiệu suất và hiệu quả. Mô hình này có những đặc điểm nổi bật sau:
- Là mô hình chỉ xử lý văn bản (text-only) được huấn luyện theo hướng instruction
- Hiệu suất vượt trội so với Llama 3.1 70B
- Khả năng xử lý tương đương Llama 3.1 405B nhưng tiêu tốn ít tài nguyên hơn đáng kể
- Hỗ trợ đa ngôn ngữ và vượt trội trong các benchmark ngành
Các Tính Năng Chính
1. Khả Năng Xử Lý Đa Dạng
- Đối thoại đa ngôn ngữ
- Tóm tắt văn bản
- Suy luận phức tạp
- Hiểu biết toán học
- Kiến thức tổng quát
- Thực hiện theo hướng dẫn chính xác
2. Ứng Dụng Trong Doanh Nghiệp
- Phát triển ứng dụng doanh nghiệp
- Tạo nội dung
- Nghiên cứu nâng cao
- Tạo dữ liệu tổng hợp
- Cải thiện các mô hình khác
3. Truy cập thực tế trong Bedrock
Tôi chọn Region US East (N. Virginia) để kiểm tra
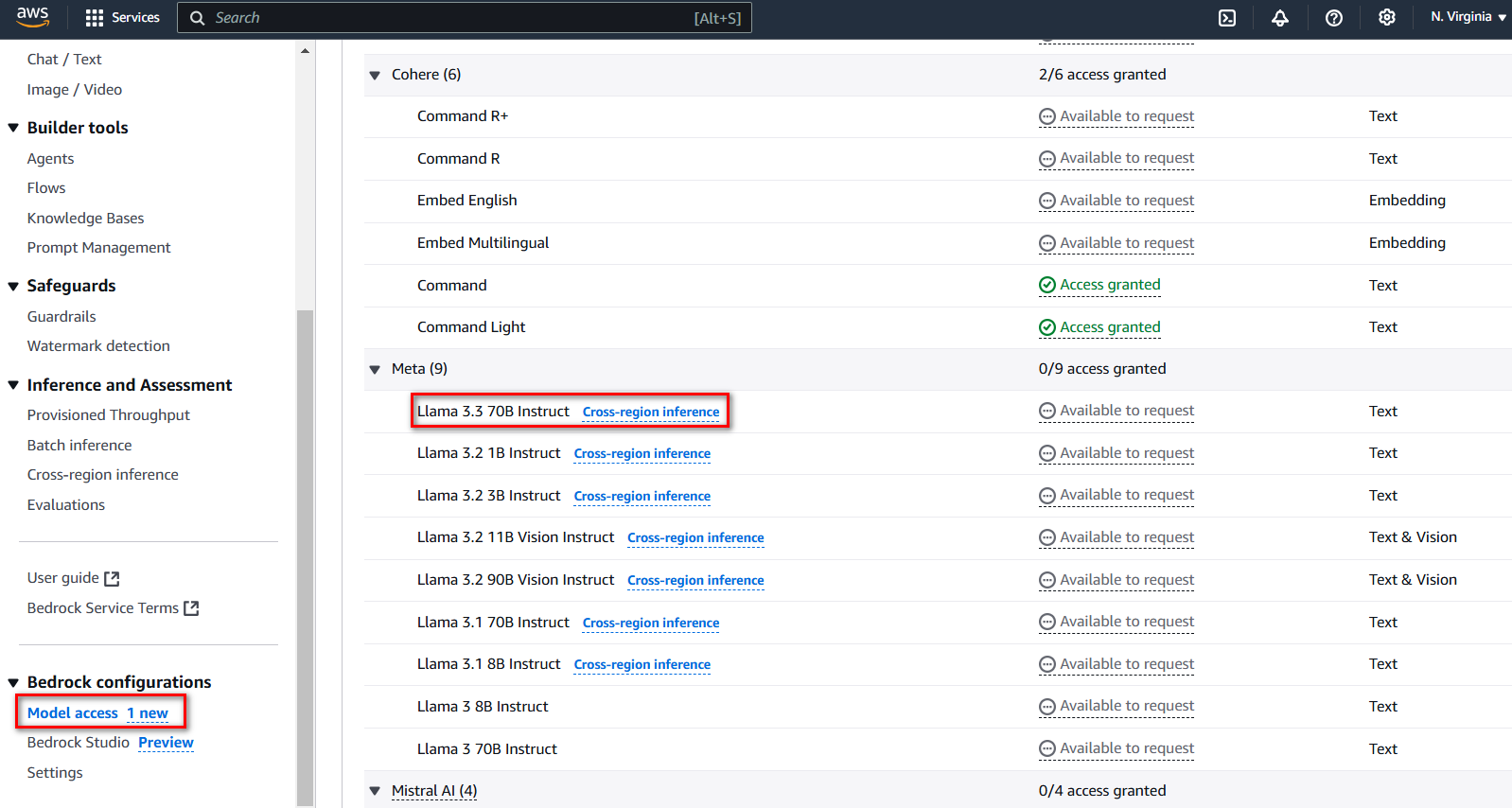
Chọn Amazon Bedrock → Bedrock configurations → Model access
Bạn sẽ thấy Llama 3.3 70B Instruct hiện đã có sẵn
Hướng Dẫn Tích Hợp
Cấu Trúc Request
{
"prompt": string,
"temperature": float,
"top_p": float,
"max_gen_len": int
}Các Tham Số Chính:
- prompt (Bắt buộc)
- Là nội dung đầu vào cho mô hình
- Cần tuân thủ format đặc biệt cho hội thoại
- temperature (Tùy chọn)
- Mặc định: 0.5
- Phạm vi: 0-1
- Điều chỉnh độ ngẫu nhiên trong câu trả lời
- top_p (Tùy chọn)
- Mặc định: 0.9
- Phạm vi: 0-1
- Kiểm soát xác suất lựa chọn token
- max_gen_len (Tùy chọn)
- Mặc định: 512
- Phạm vi: 1-2048
- Giới hạn độ dài của câu trả lời
Ví Dụ Code Python
import json
import logging
import boto3
from botocore.exceptions import ClientError
def generate_text(model_id, body):
logger.info("Generating text with Meta Llama model %s", model_id)
bedrock = boto3.client(service_name='bedrock-runtime')
response = bedrock.invoke_model(
body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
return response_body
def main():
model_id = "meta.llama3.3-70b"
prompt = """<s>[INST] <<SYS>>
Bạn là một trợ lý AI hữu ích, tôn trọng và trung thực.
<</SYS>>
Hãy giải thích về trí tuệ nhân tạo? [/INST]"""
body = json.dumps({
"prompt": prompt,
"max_gen_len": 128,
"temperature": 0.1,
"top_p": 0.9
})
try:
response = generate_text(model_id, body)
print(f"Văn bản sinh ra: {response['generation']}")
print(f"Số token prompt: {response['prompt_token_count']}")
print(f"Số token sinh ra: {response['generation_token_count']}")
except ClientError as err:
logger.error("Lỗi client: %s", err.response["Error"]["Message"])
if __name__ == "__main__":
main()Khả Năng Triển Khai
Llama 3.3 70B hiện có sẵn trên Amazon Bedrock tại các region:
- US East (Ohio)
- US East (N. Virginia) – thông qua cross-region inference
- US West (Oregon) – thông qua cross-region inference
Lưu Ý Quan Trọng
- Geofencing: Một số phiên bản như Llama 3.2 và 3.3 có giới hạn về khu vực sử dụng
- Format Prompt: Cần tuân thủ cấu trúc đặc biệt khi tạo prompt cho mô hình
- Tối Ưu Hóa: Điều chỉnh các tham số như temperature và top_p để có kết quả tốt nhất
Kết Luận
Vậy là hôm nay tôi đã chia sẻ Llama 3.3 70B trên Amazon Bedrock. Hy vọng trong tương lai, có thể ứng dụng và vận hành trong kỷ nguyên trí tuệ nhân tạo.
Cảm ơn các bạn đã đọc đến cuối bài viết!
Để lại một bình luận