Mục lục bài viết
1. Giới thiệu về Amazon Kendra
Amazon Kendra là dịch vụ tìm kiếm doanh nghiệp thông minh được hỗ trợ bởi machine learning, cho phép người dùng tìm kiếm thông tin chính xác và phù hợp từ nhiều nguồn dữ liệu khác nhau. Với các mô hình ngôn ngữ lớn tích hợp, Kendra cung cấp trải nghiệm tìm kiếm tương tác và chính xác cao.
Các Tính Năng Chính
- Tìm kiếm thông minh dựa trên ML
- Tích hợp nhiều nguồn dữ liệu
- Tùy chỉnh kết quả tìm kiếm
2. Quy trình Triển khai:
2.1 Chuẩn bị dữ liệu
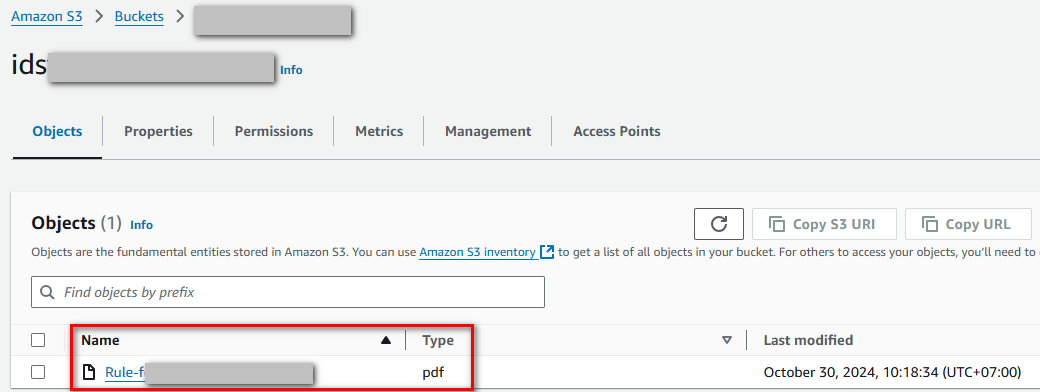
. Tạo bucket S3 để lưu trữ dữ liệu(CSV, PDF, …)
2.2 Tạo Index trong Kendra
Truy cập AWS Console và tìm dịch vụ Kendra
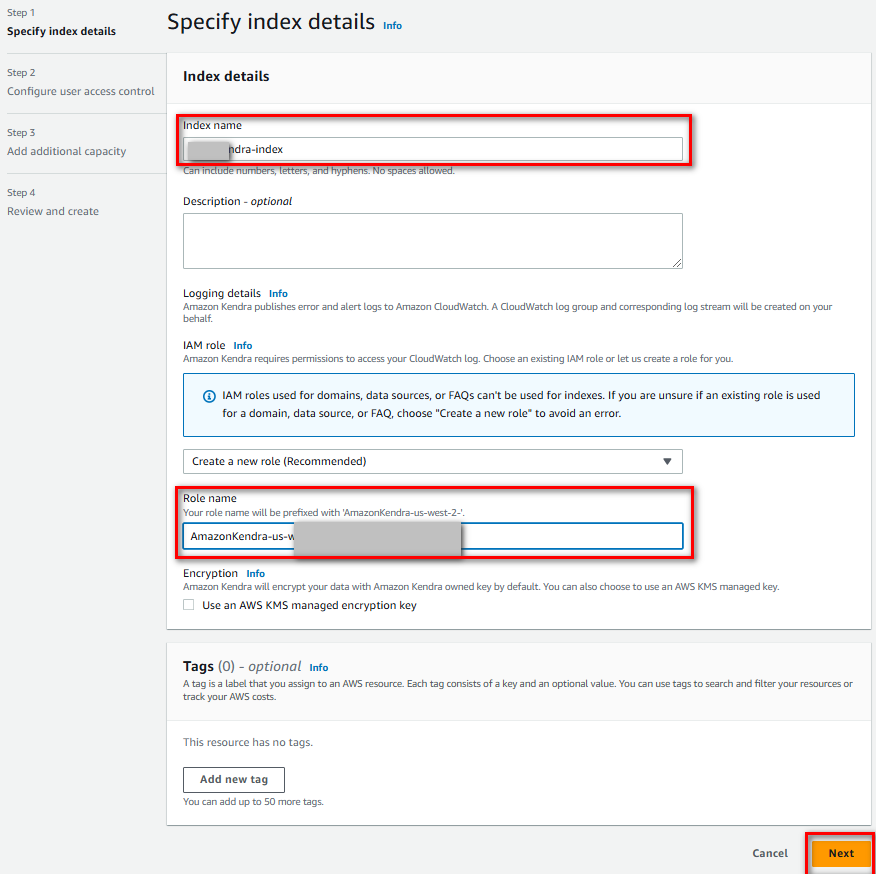
Tạo Index mới bằng cách nhấn “Create an Index”

Đặt tên Index, tạo hoặc chọn IAM Role, nhấn “Next”
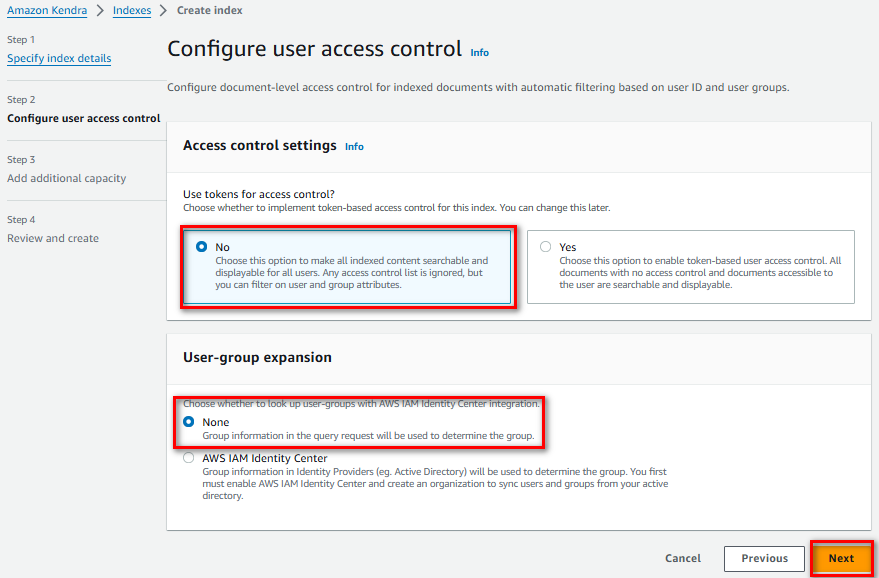
Cấu hình Access control settings là “No”, User-group expansion là “None”, nhấn “Next”
Chọn Edition là “Developer Edition”, nhấn “Next”
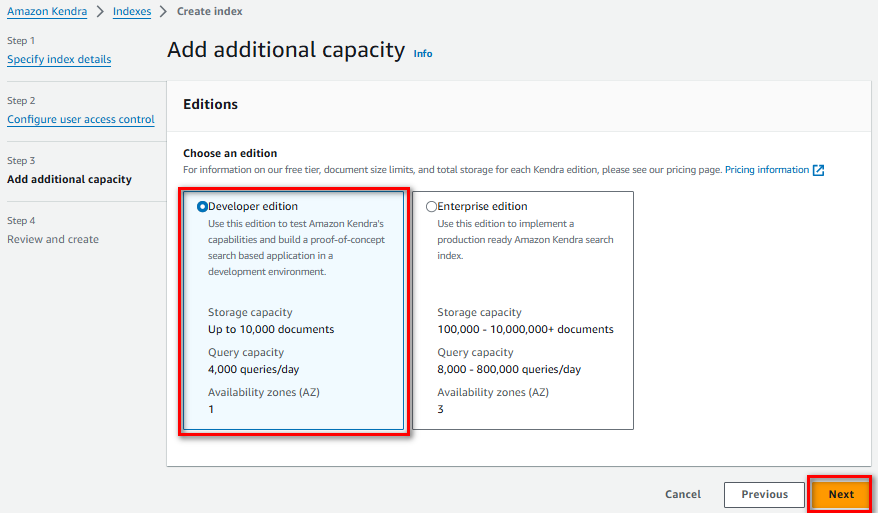
Lưu ý về Developer Edition:
- Hỗ trợ 10,000 tài liệu
- Phù hợp cho proof of concept
- Chạy trên một availability zone
Cuối cùng nhấn “Create” để tạo index
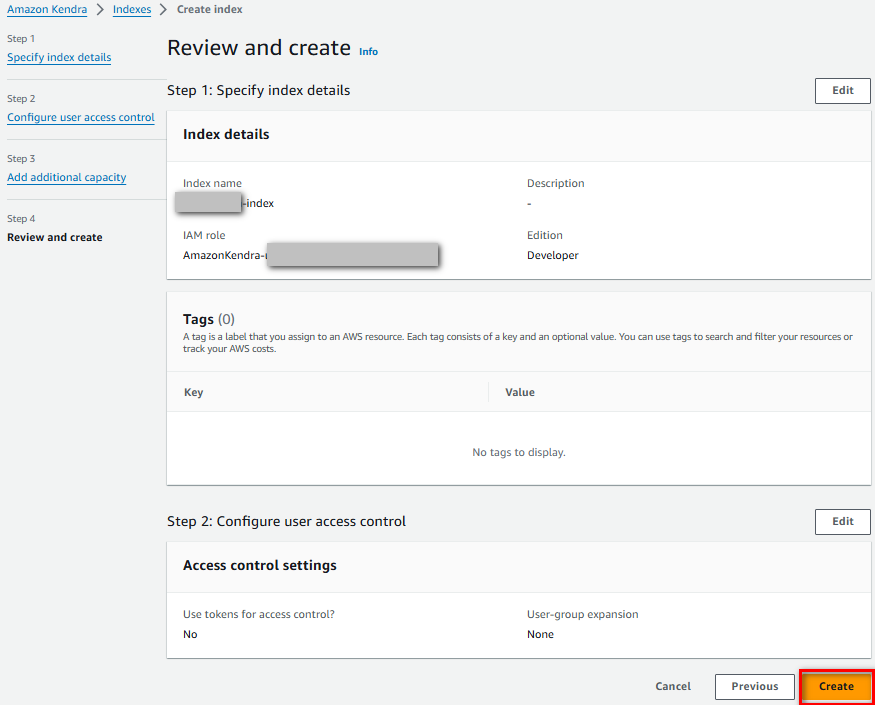
Ta có kết quả index đã được tạo
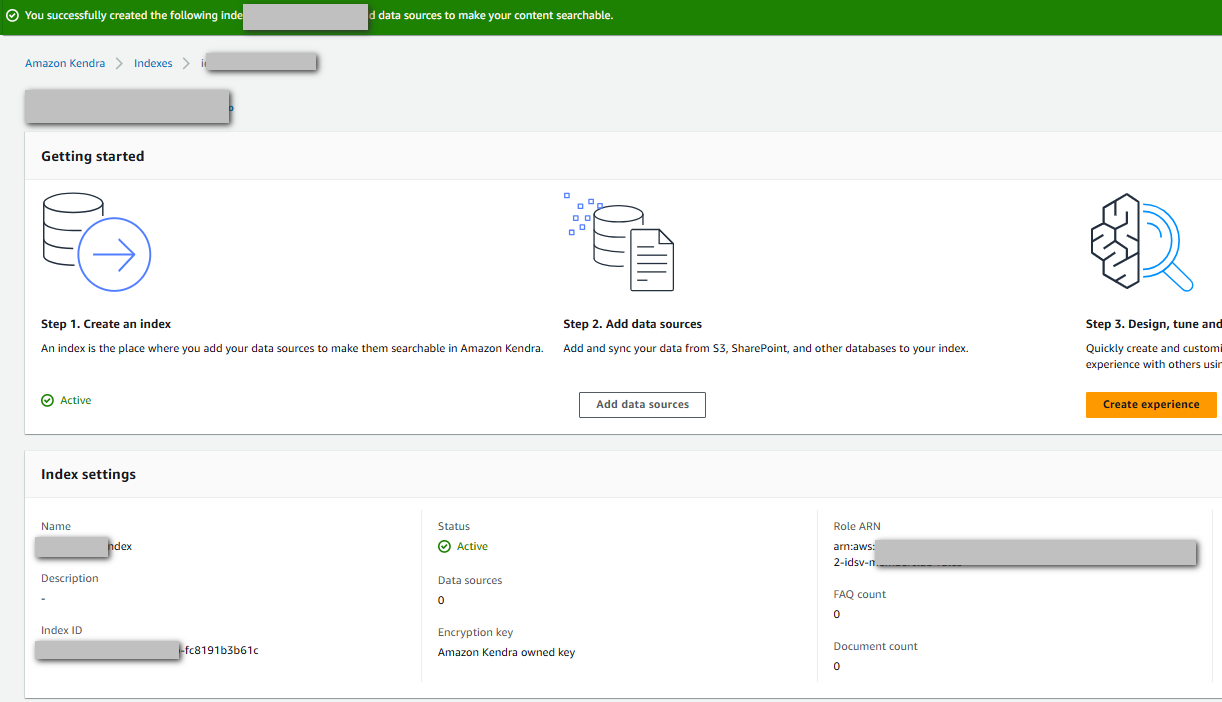
2.3 Cấu hình Data Source
Chọn loại Data Source có sẵn, ở bài này tôi chọn S3
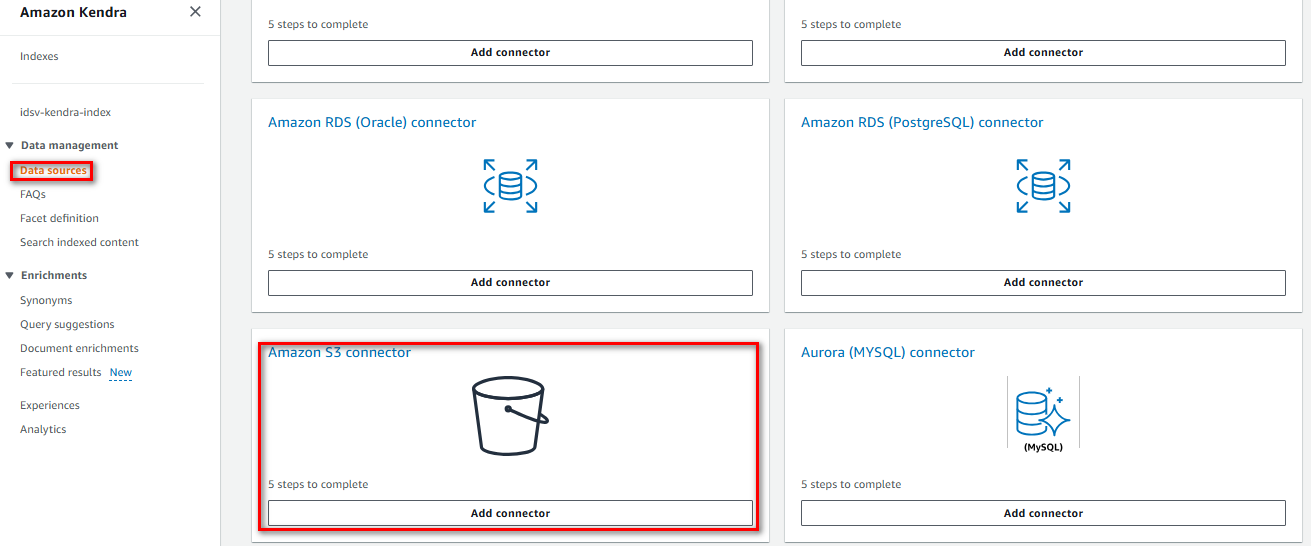
Cấu hình S3 Connector
Đặt tên data source, nhấn “Next”
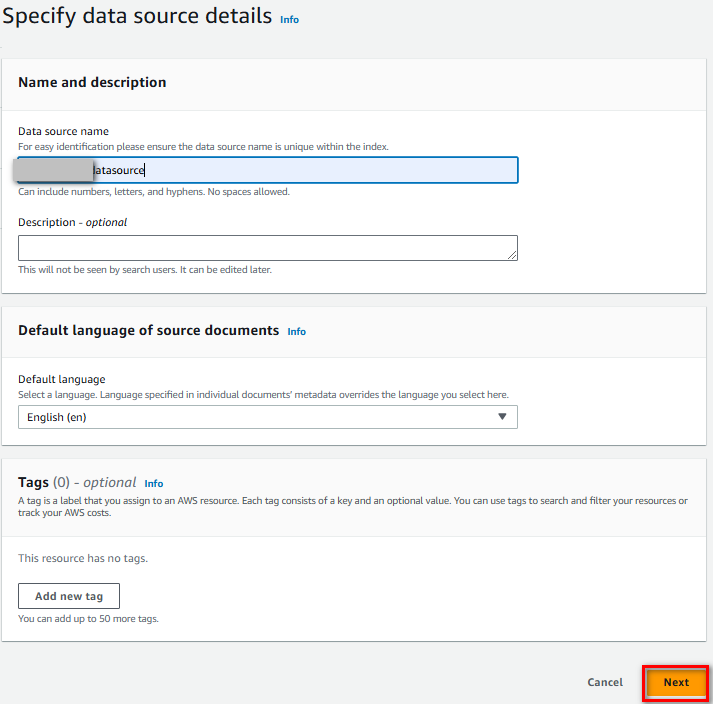
Tạo IAM role cho connector, nhấn “Next”
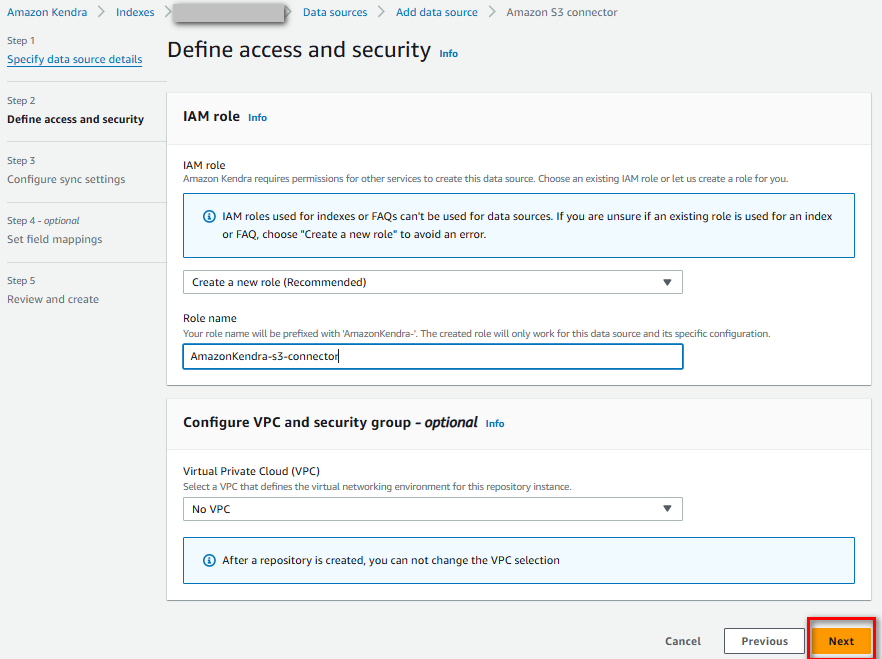
Cấu hình các mục cần thiết, nhấn “Next”
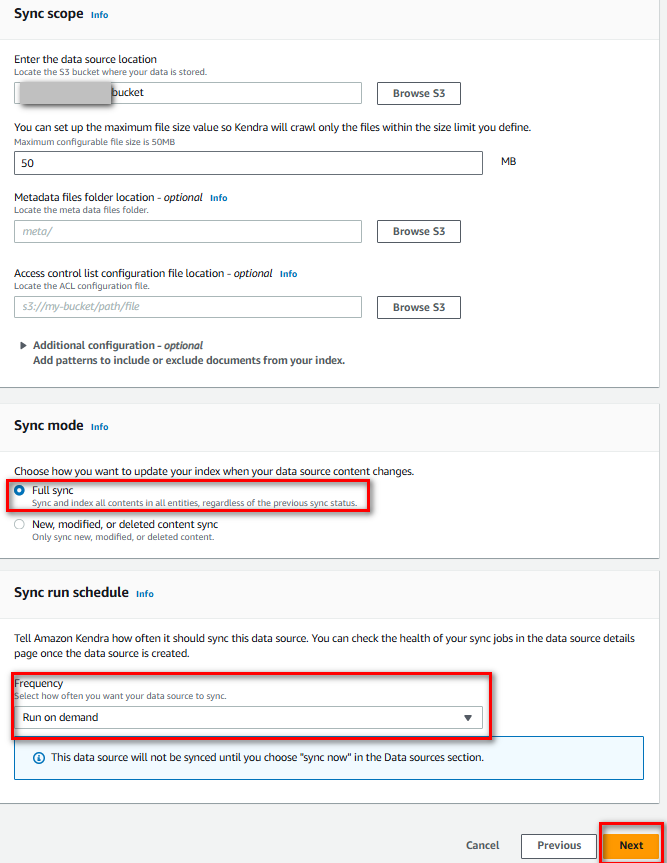
Enter the data source location (Trỏ tới bucket s3 đã tạo)
Sync mode = Full sync
Sync run schedule = Run on demand
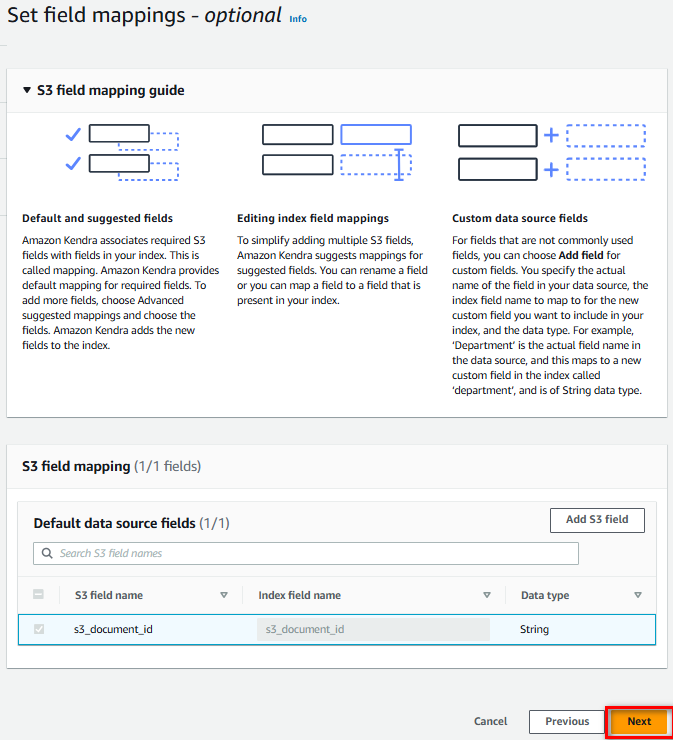
Để mặc định S3 field mapping “s3_document_id”, nhấn “Next”
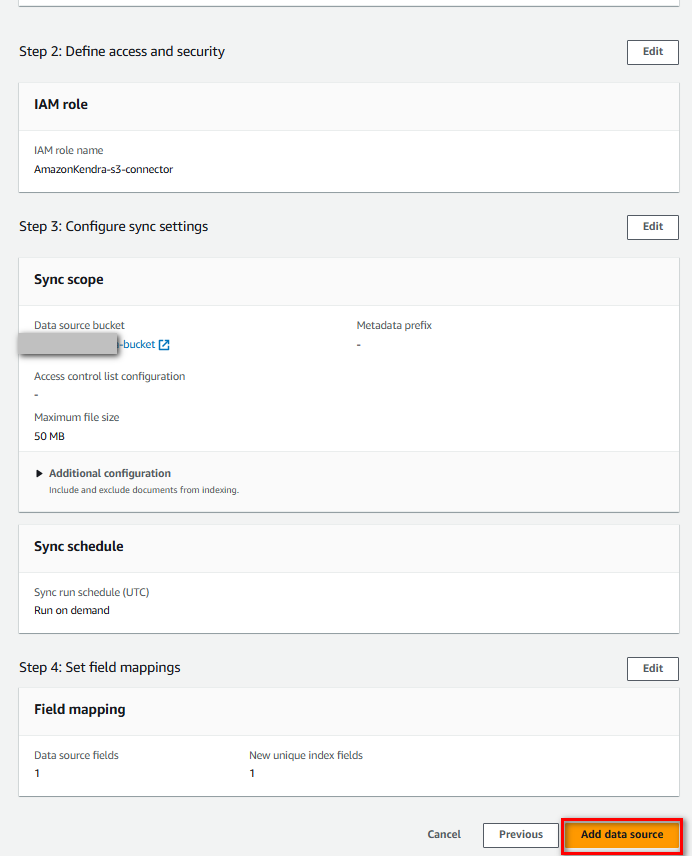
Cuối cùng nhấn “Add data source”
2.4 Đồng bộ và Kiểm tra
Sau khi cấu hình, nhấn “”Sync now” để bắt đầu crawl dữ liệu
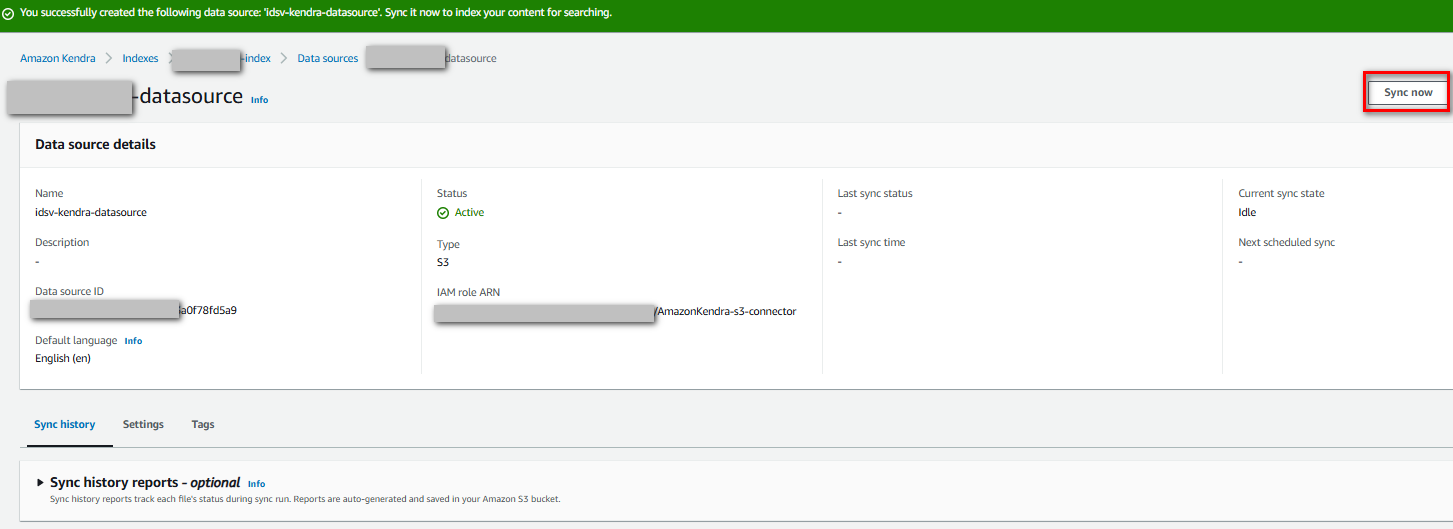
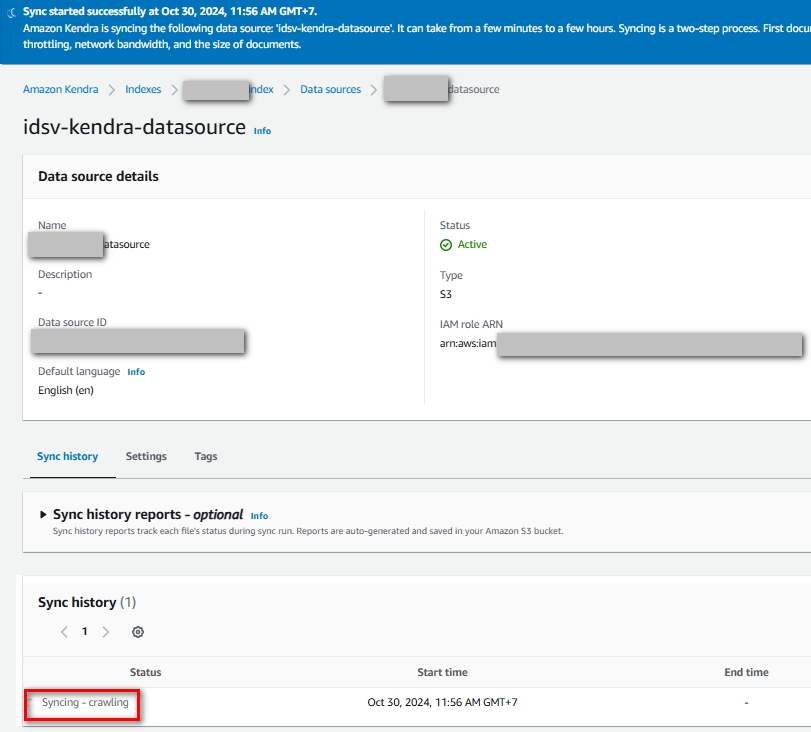
Đã crawl dữ liệu thành công
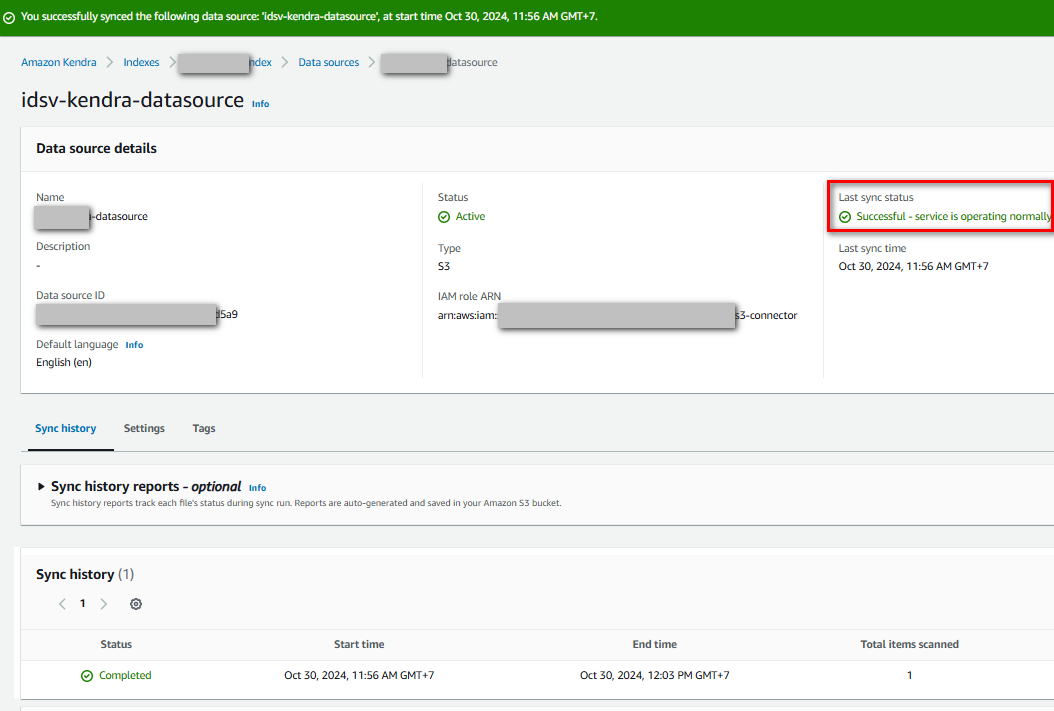
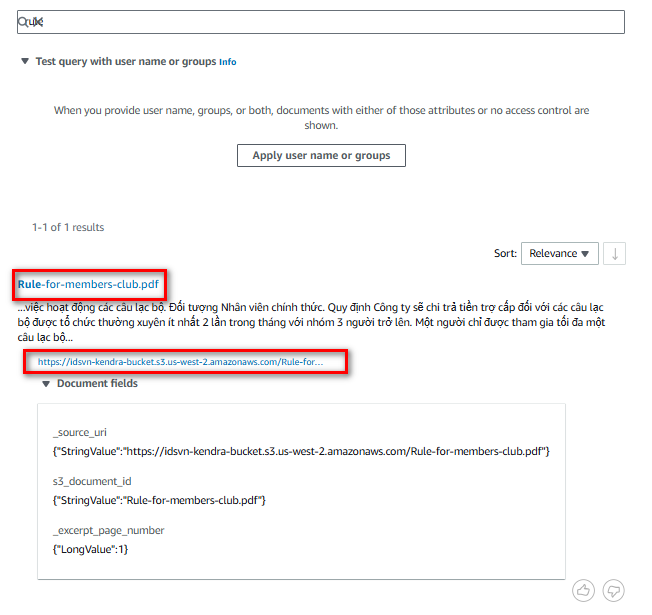
Bây giờ, chúng ta có thể test thử tính năng search index đã tạo ra
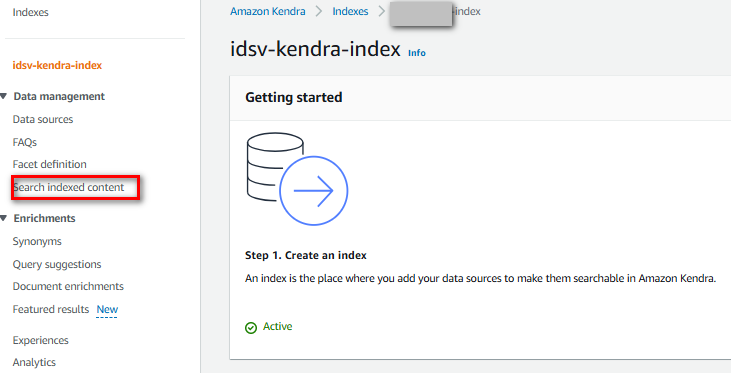
Test thử, tôi thấy trỏ tới đúng file PDF có trong s3
Kết luận
Amazon Kendra cung cấp giải pháp tìm kiếm doanh nghiệp mạnh mẽ, tích hợp machine learning để cải thiện độ chính xác và trải nghiệm người dùng. Hy vọng bài viết này hữu ích cho các nhà phát triển đang tìm kiếm giải pháp search với độ chính xác cao.
Để lại một bình luận