Mục lục bài viết
- 1. Tổng quan về Model Distillation
- 2. Cách Model Distillation Hoạt động
- 3. Hướng dẫn Triển khai
- 4. Best Practices
- 5. Chi phí & Availability
- Kết luận
AWS vừa công bố tính năng Model Distillation cho Amazon Bedrock – giúp tối ưu hóa hiệu suất và chi phí cho các mô hình AI. Chi tiết tham khảo ở đây
https://aws.amazon.com/about-aws/whats-new/2024/12/amazon-bedrock-model-distillation-preview
1. Tổng quan về Model Distillation
1.1. Model Distillation là gì?
Model Distillation(Chưng cất model) là kỹ thuật chuyển giao kiến thức từ một mô hình lớn (teacher model) sang một mô hình nhỏ hơn (student model). Mục tiêu là giúp mô hình nhỏ hơn có thể:
- Hoạt động nhanh hơn
- Tiết kiệm chi phí đào tạo model hơn
1.2. Tại sao cần Model Distillation?
- Thách thức hiện tại:
- Mô hình lớn thì có độ trễ cao
- Chi phí vận hành rất đắt đỏ khi scale
- Mô hình nhỏ lại thiếu độ chính xác
- Fine-tuning đòi hỏi kỹ năng và dữ liệu chất lượng
- Lợi ích mang lại:
- Giảm độ trễ đáng kể
- Tối ưu chi phí vận hành
- Duy trì độ chính xác cao
- Tự động hóa quá trình training
2. Cách Model Distillation Hoạt động
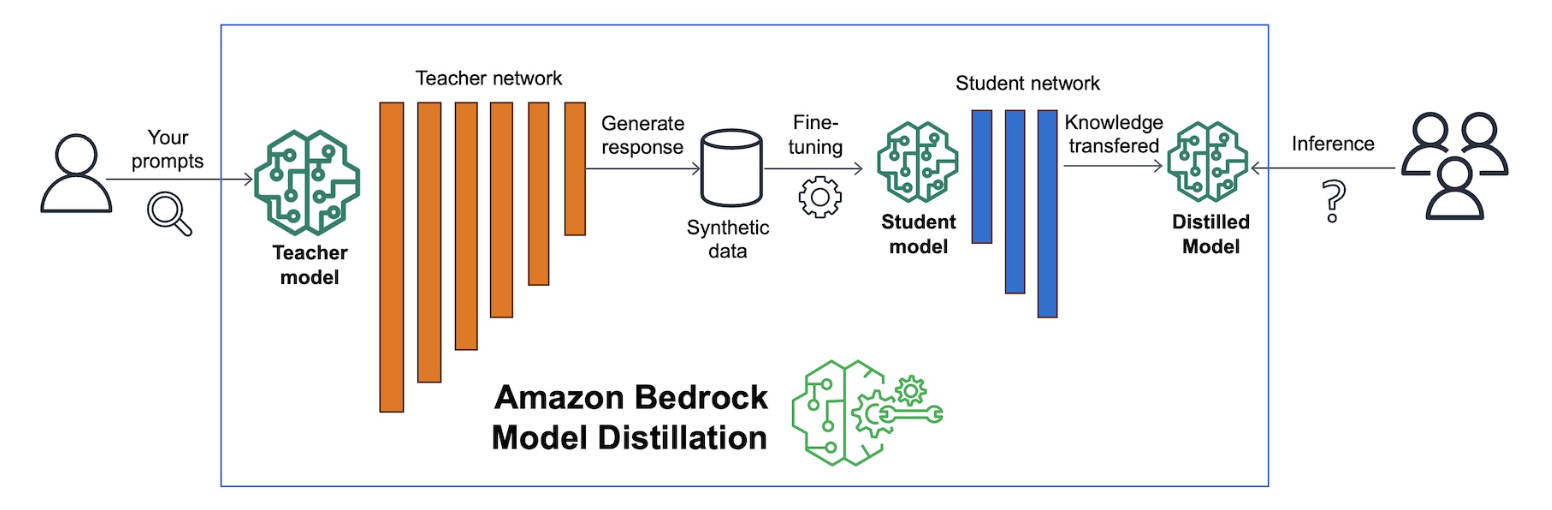
2.1. Quy trình tổng thể
- Sinh dữ liệu từ Teacher Model:
- Tạo responses từ mô hình lớn
- Áp dụng kỹ thuật data synthesis
- Tạo training dataset chất lượng cao
- Fine-tune Student Model:
- Chuyển giao kiến thức từ teacher
- Tối ưu hóa cho use case cụ thể
- Đánh giá và điều chỉnh
2.2. Các kỹ thuật Data Synthesis
Amazon Bedrock sử dụng nhiều kỹ thuật data synthesis:
- Tạo prompt tương tự để mở rộng dataset
- Tự động điều chỉnh phương pháp phù hợp với use case
3. Hướng dẫn Triển khai
3.1. Tạo Distillation Job
Vào Amazon Bedrock console → Custom models → Create Distillation job
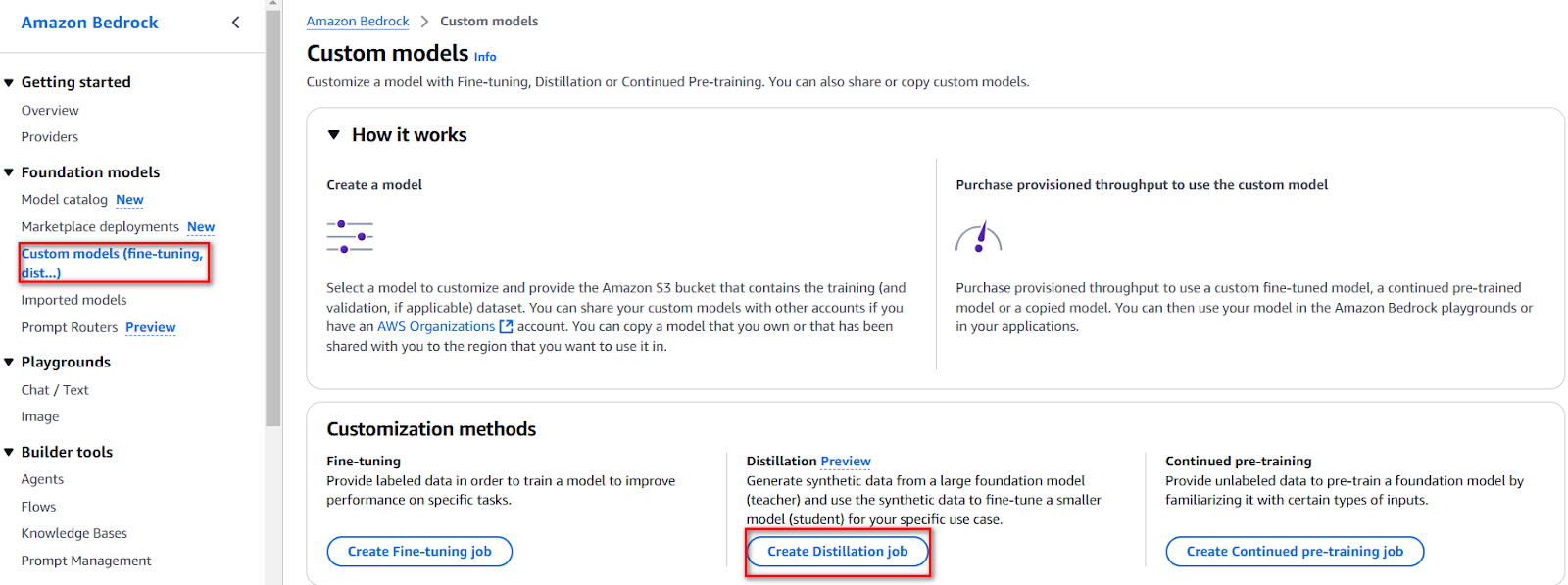
Đặt tên cho distilled model, đặt tên job, chọn teacher và student model
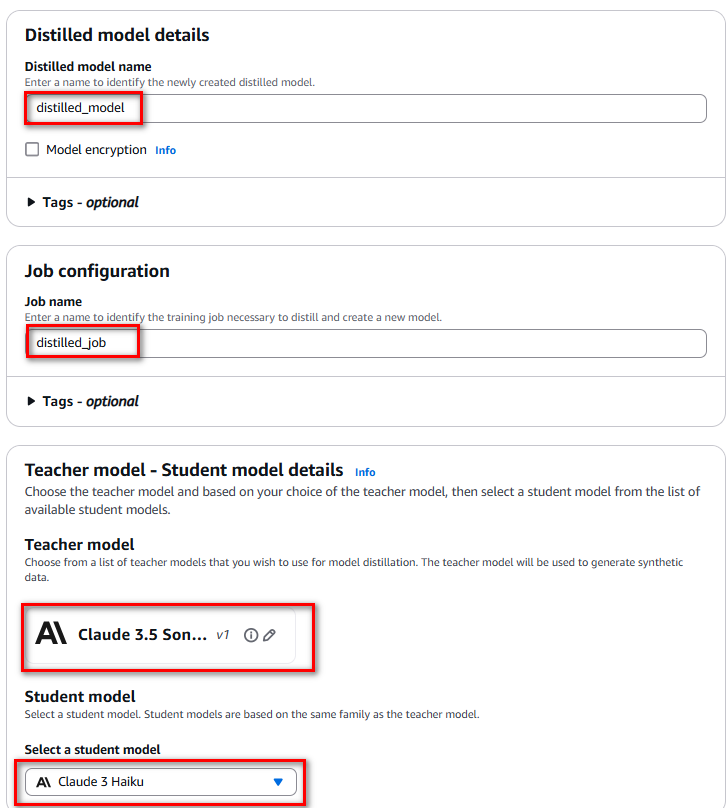
Thiết lập Max response length, chọn input dataset từ S3, cấu hình output metrics, sau đó nhấn “Create Distillation job” để tạo job cho việc chưng cất model
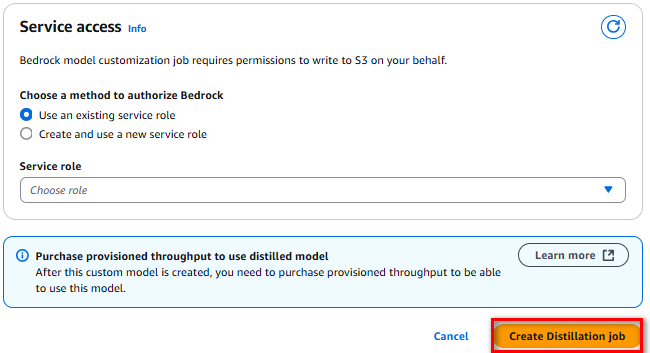
3.2. Sử dụng Production Data
Thêm request metadata giúp dễ dàng lọc nhật ký gọi tại một thời điểm.
Code mẫu để logging production data:
request_params = {
'modelId': 'meta.llama3-1-405b-instruct-v1:0',
'messages': [
{
'role': 'user',
'content': [
{
"text": "What is model distillation in generative AI?"
}
]
}
},
'requestMetadata': {
"ProjectName": "distilled_model",
"CodeName": "mydistilled_code"
}
}
response = bedrock_runtime_client.converse(**request_params)
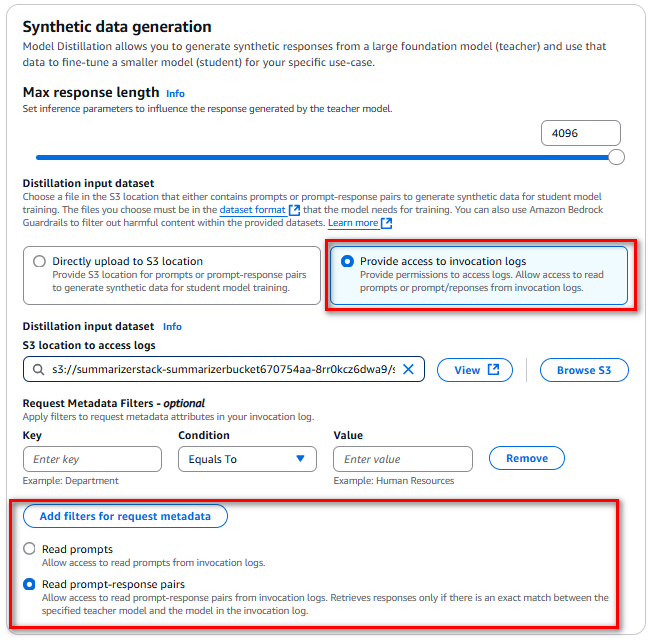
pprint(response)Tiếp theo, khi sử dụng Amazon Bedrock Model Distillation, chọn teacher model có độ chính xác mà bạn muốn hướng đến cho trường hợp sử dụng của mình và một student model mà bạn muốn tinh chỉnh.
Sau đó, cấp quyền truy cập cho Amazon Bedrock để đọc nhật ký gọi của bạn.
Tại đây, có thể chỉ định request metadata filters để chỉ các nhật ký cụ thể, hợp lệ cho trường hợp sử dụng của bạn, được đọc để tinh chỉnh student model.
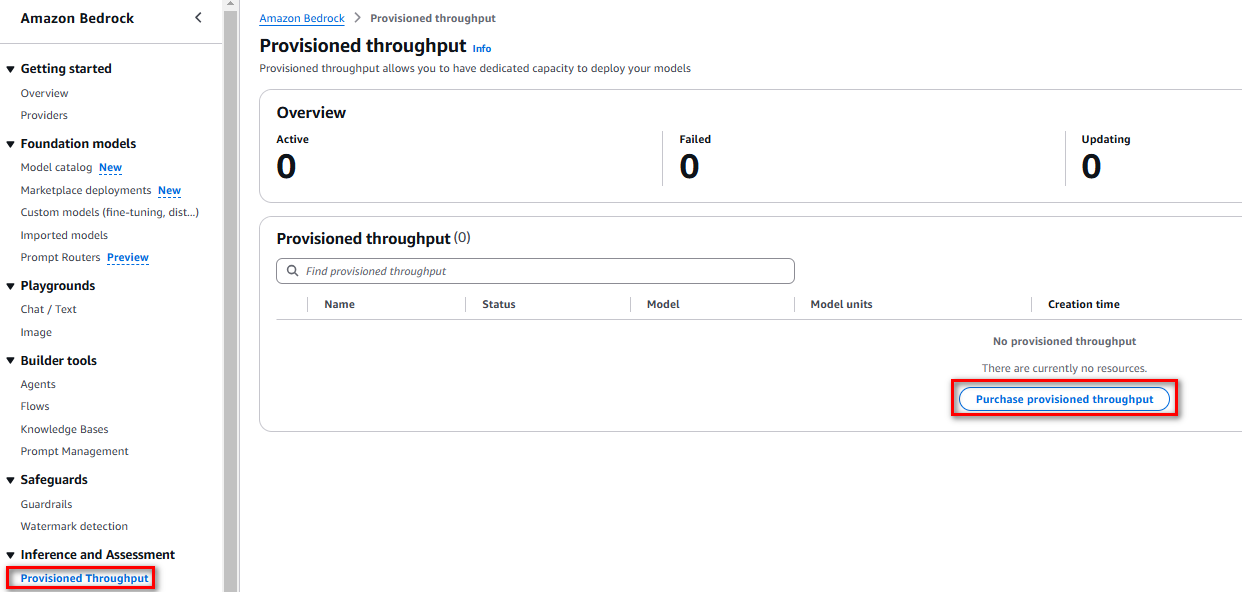
3.3. Hướng dẫn Inference từ model đã chứng cất
Trước khi sử dụng mô hình đã chưng cất, cần mua Provisioned Throughput(thông lượng) cho Amazon Bedrock, sau đó sử dụng mô hình đã chưng cất để inference(suy luận).
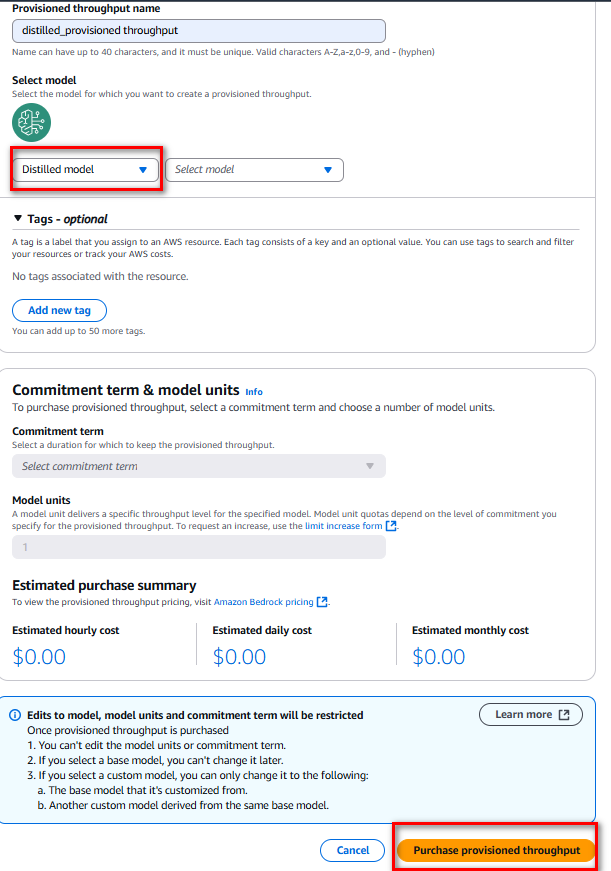
Khi mua Provisioned Throughput, chọn một điều khoản cam kết, chọn số lượng đơn vị mô hình và kiểm tra chi phí ước tính theo giờ, ngày và tháng.
4. Best Practices
4.1. Trước khi bắt đầu cần
- Đánh giá Teacher Model:
- Test nhiều teacher models
- Chọn model phù hợp use case
- Tối ưu prompts
- Lựa chọn Student Model:
- Đánh giá latency profile
- Xem xét yêu cầu về hiệu suất
- Cân nhắc chi phí vận hành
4.2. Khuyến nghị Triển khai
- Dataset:
- Chuẩn bị dữ liệu chất lượng cao
- Đảm bảo đa dạng examples
- Tuân thủ format yêu cầu
- Monitoring:
- Theo dõi độ chính xác
- Đánh giá chi phí-hiệu quả
5. Chi phí & Availability
5.1. Chi phí
- Training Phase:
- Chi phí sinh dữ liệu từ teacher model
- Chi phí fine-tune student model
- Chi phí lưu trữ model
- Inference Phase:
- Tính theo Provisioned Throughput
- Tính theo giờ/model unit
- Chi phí storage hàng tháng
5.2. Availability
- Khả dụng tại US East (N. Virginia)
- Khả dụng tại US West (Oregon)
- Hỗ trợ models từ Anthropic, Meta và Amazon
Kết luận
Vậy là Amazon Bedrock đã có tính năng mới Model Distillation giúp tối ưu hóa hiệu suất và chi phí cho các ứng dụng AI. Trong thế giới AI, tối ưu hoá hiệu suất và chi phí là 2 bài toán cần được quan tâm cao nhất trong thực tế.
Hy vọng bài viết này có thể giúp ích cho độc giả trong tương lai.
Và xin cảm ơn rất nhiều các bạn đã đọc đến cuối bài viết!
Để lại một bình luận